아래 Medium 블로그로 이전합니다.
'AWS' 카테고리의 다른 글
| Amazon MemoryDB for Redis (0) | 2022.06.13 |
|---|---|
| AWS EFS (0) | 2021.09.08 |
| DynamoDB 특징에 대해 알아보자 (0) | 2021.08.23 |
| Amazon Aurora 알아보자 (0) | 2021.08.23 |
| AWS Pinpoint (0) | 2021.06.17 |
아래 Medium 블로그로 이전합니다.
| Amazon MemoryDB for Redis (0) | 2022.06.13 |
|---|---|
| AWS EFS (0) | 2021.09.08 |
| DynamoDB 특징에 대해 알아보자 (0) | 2021.08.23 |
| Amazon Aurora 알아보자 (0) | 2021.08.23 |
| AWS Pinpoint (0) | 2021.06.17 |
update-cluster --cluster-name my-cluster --shard-configuration ShardCount=5| AWS 블로그 이전합니다. (0) | 2023.05.08 |
|---|---|
| AWS EFS (0) | 2021.09.08 |
| DynamoDB 특징에 대해 알아보자 (0) | 2021.08.23 |
| Amazon Aurora 알아보자 (0) | 2021.08.23 |
| AWS Pinpoint (0) | 2021.06.17 |
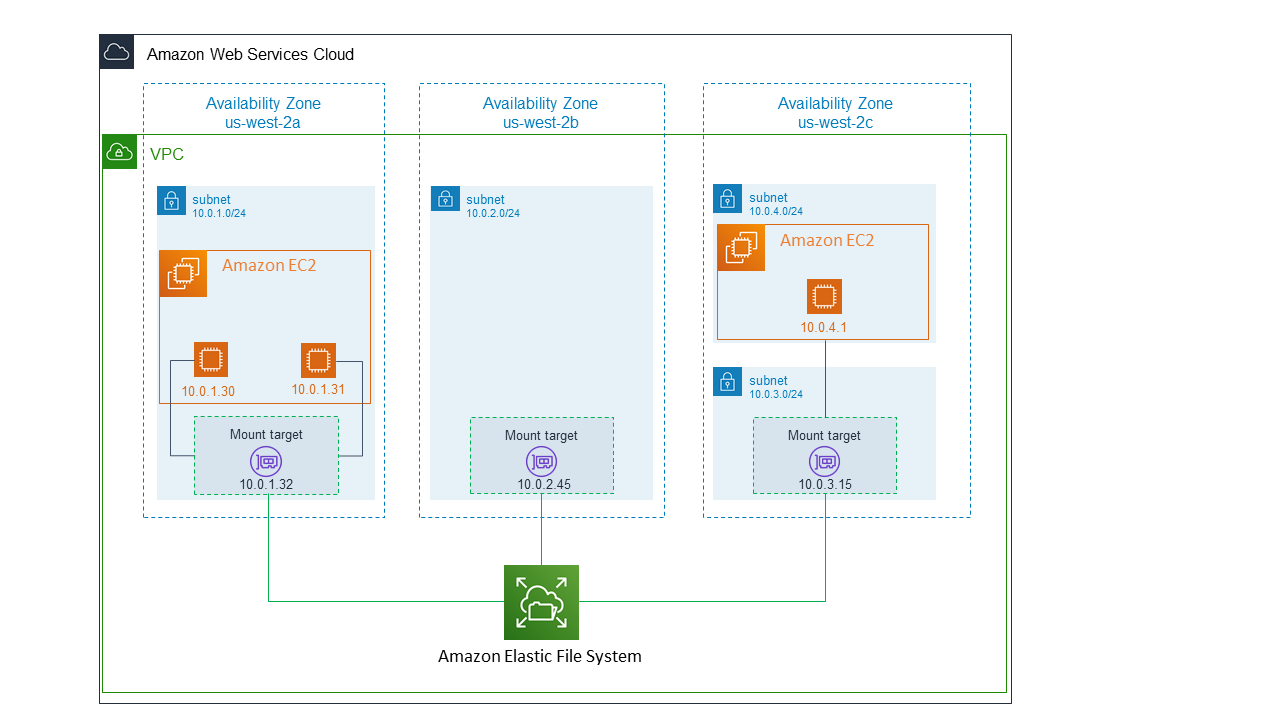
| AWS 블로그 이전합니다. (0) | 2023.05.08 |
|---|---|
| Amazon MemoryDB for Redis (0) | 2022.06.13 |
| DynamoDB 특징에 대해 알아보자 (0) | 2021.08.23 |
| Amazon Aurora 알아보자 (0) | 2021.08.23 |
| AWS Pinpoint (0) | 2021.06.17 |
| Amazon MemoryDB for Redis (0) | 2022.06.13 |
|---|---|
| AWS EFS (0) | 2021.09.08 |
| Amazon Aurora 알아보자 (0) | 2021.08.23 |
| AWS Pinpoint (0) | 2021.06.17 |
| AWS SAM (Serverless Application Model) (0) | 2021.04.29 |
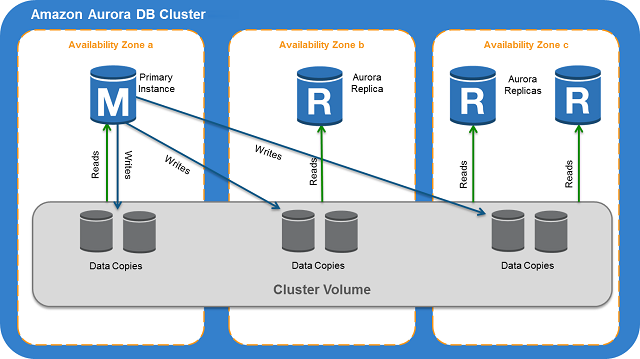

자동으로 장애조치를 하며, 관리자의 개입없이도 장애조치가 작용된다.

기존 aurora는 클러스터 내 읽기/쓰기가 가능한 마스터 노드는 1개만 구성하였고, 최대 15개의 읽기 복제본만 구성(읽기 성능만 확장)할 수 있었다.
Multi-Masters의 출시로 이제는 읽기/쓰기가 모두 가능한 마스터 노드를 2개 이상 구성할 수 있게 되어, 읽기/쓰기 성능 모두 확장 가능하게 되었다. (2019년에 정식버전으로 병합)
따라서 고가용성과 성능을 보장할 수 있게됨
| AWS EFS (0) | 2021.09.08 |
|---|---|
| DynamoDB 특징에 대해 알아보자 (0) | 2021.08.23 |
| AWS Pinpoint (0) | 2021.06.17 |
| AWS SAM (Serverless Application Model) (0) | 2021.04.29 |
| CloudEndure (서버 마이그레이션 툴), SMS (0) | 2021.03.29 |
fred@domainfred+foo@domain) ChannelType,Address,User.UserId,User.UserAttributes.FirstName,User.UserAttributes.LastName,User.UserAttributes.age,User.UserAttributes.isActive
EMAIL,Raymond+pinpoint1@emaildomain.com,userid1,Raymond,Phillips,35,TRUE
EMAIL,Sue+pinpoint2@emaildomain.com,userid2,Sue,Sherman,31,FALSE
EMAIL,Mark+pinpoint3@emaildomain.com,userid3,Mark,Price,28,isActive 속성을 활용하여 활성/비활성 사용자에 대해 세그먼트 분류 가능Hi {{User.UserAttributes.FirstName}}, congratulations on your new {{User.UserAttributes.Activity}} record of {{User.UserAttributes.PersonalRecord}}!)multivalidate split 분기로 이메일 클릭/ 이메일 오픈 / 수신 거부 등의 분기 처리 가능Yes/no split을 통해 특정 로직이 지나간 후에 기존 세그먼트의 유저가 그대로 남아 있는지 확인 가능 (동일 세그먼트로 조건 평가를 추가하면 됨)| DynamoDB 특징에 대해 알아보자 (0) | 2021.08.23 |
|---|---|
| Amazon Aurora 알아보자 (0) | 2021.08.23 |
| AWS SAM (Serverless Application Model) (0) | 2021.04.29 |
| CloudEndure (서버 마이그레이션 툴), SMS (0) | 2021.03.29 |
| AWS Systems Manager (SSM) (0) | 2021.03.15 |