Kafka & Confluent
kafka : 데이터를 전송해주는 메시징 플랫폼. 동시에 데이터를 실시간으로 처리하는 플랫폼
- 분산 트랜잭션 로그로 구성된 확장 가능한 Pub/Sub 메시지 큐에 저장 기능이 포함된 것.
- pub/sub 데이터 모델
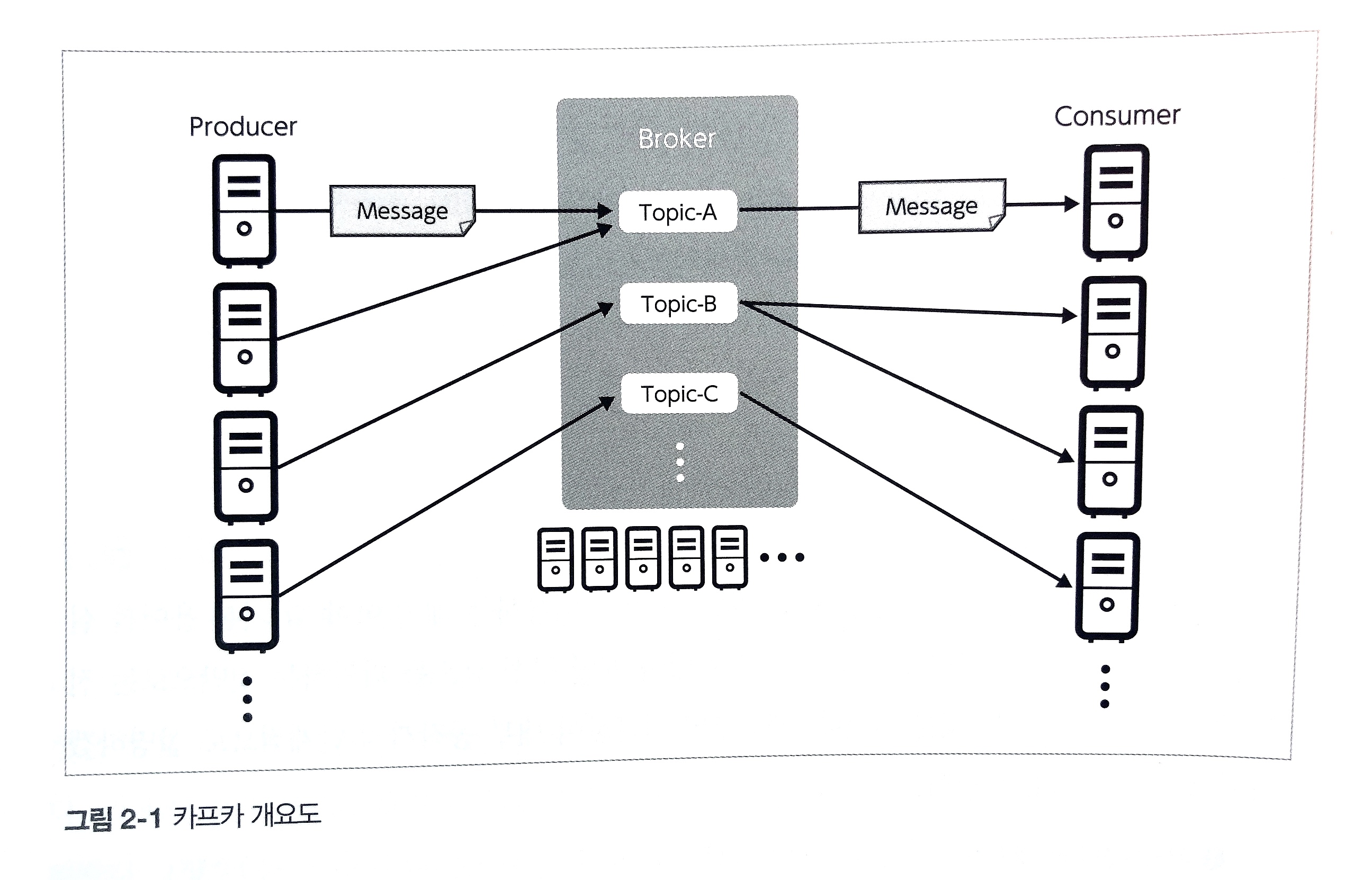
producer: kafka에 데이터를 입력하는 클라이언트- producer는 broker 중 하나의 topic만을 대상으로 데이터 입력
- topic의 파티션에 메시지를 송신할 때 프로듀서의 메모리를 사용하여 버퍼처럼 모아서 송신함
- 동일한 파티션에 보내기 위해서는? 메시지의 key-value 구조를 활용함. 동일한 key값을 가진 메시지를 동일한 id를 가진 파티션에 송신한다. 메시지 key를 지정하지 않는다면 메시지 송신은 Round-Robin 방식으로 수행됨
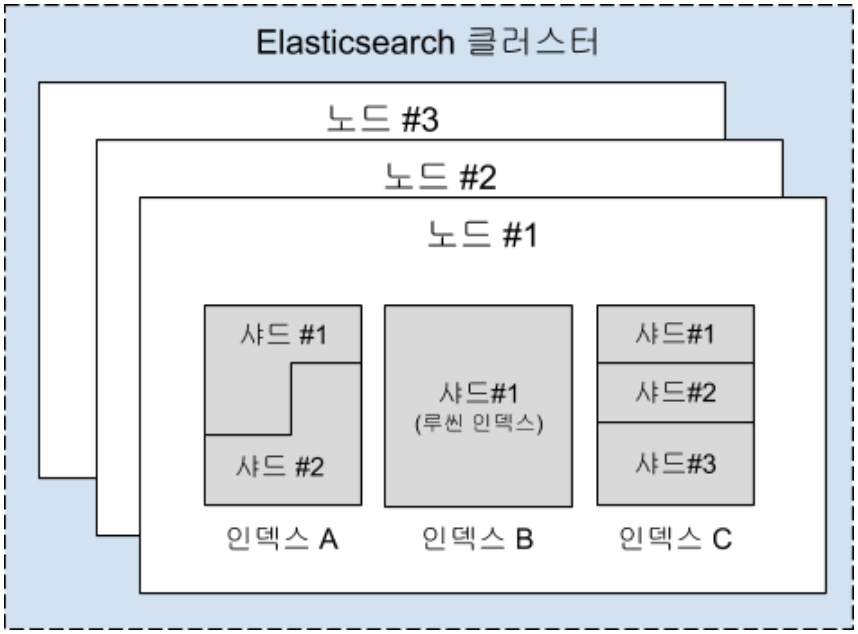
broker cluster: topic이라고 불리는 데이터 관리 유닛을 임의 개수만큼 호스팅하는 클러스터partition: 브로커 상의 데이터를 읽고 쓰는 단위- 서버 인스턴스 하나당 하나의 데몬 프로세스로 동작. 여러 대의 클러스터로 구성함으로써 throughput 향상 및 scaling이 가능해짐
- 브로커가 받은 데이터는 모두 디스크로 내보내져야 함(영속화) -> 디스크의 총 용량에 따라 데이터 보존 기간이 정해짐
consumer: kafka에서 데이터를 가져오는 클라이언트consumer group: 컨슈머 하나는 하나의 consumer group에 속함.- 수신한 메시지는 consumer group 내의 하나의 consumer가 수신받으며, 이후 consumer 사이에서 분산되어 전달됨.
- 메시지 매핑은 partition과 consumer group을 매핑하여 가능함.
- 메시지 분산 수신을 위해서는 (파티션 수 > 컨슈머 그룹 내 컨슈머)가 되어야 하며, 만족되지 않을 경우 파티션이 할당되지 않은 consumer가 발생할 수 있음
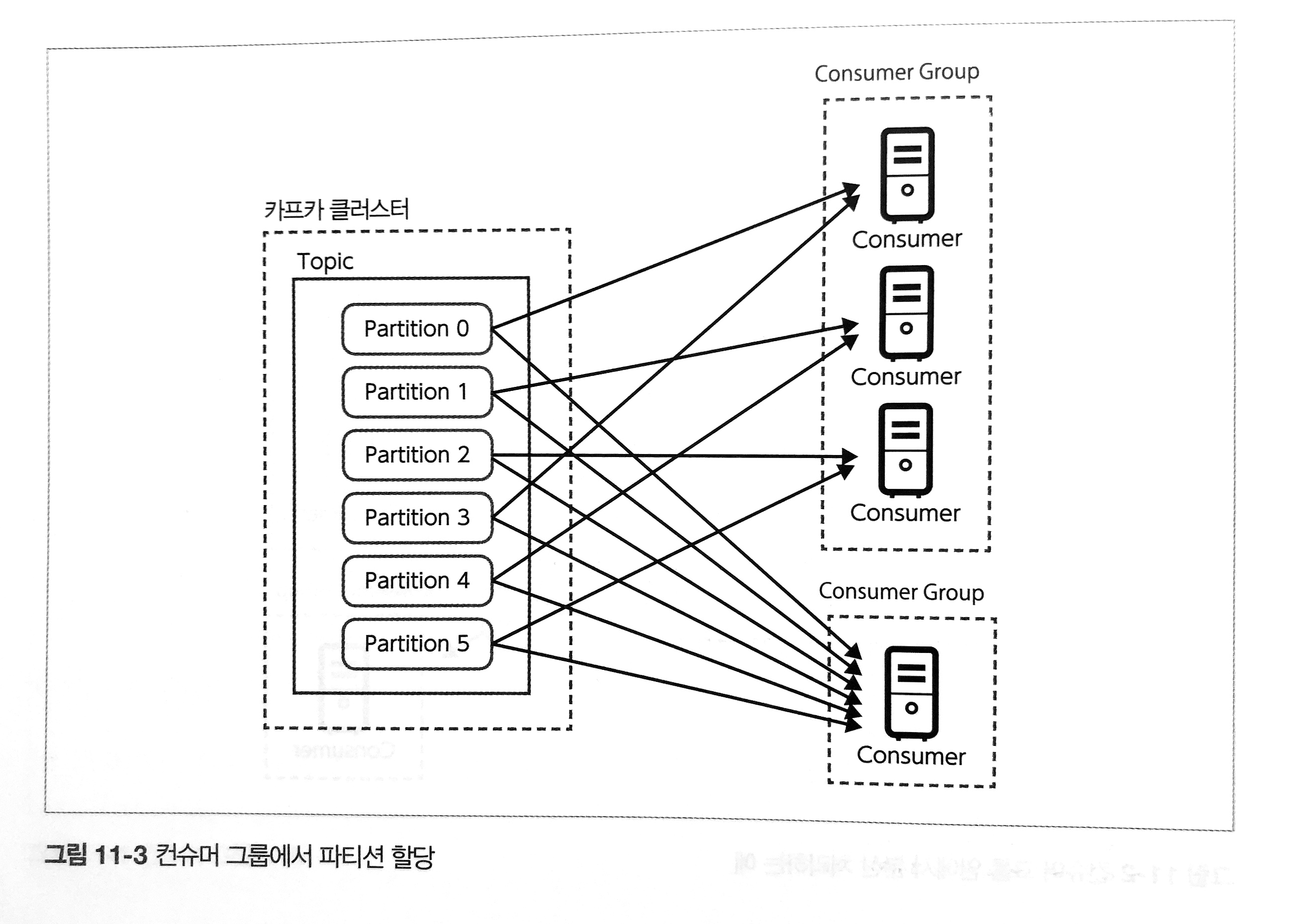
- 데이터를 가져올 topic을 지정한 후 해당 topic에서 데이터를 가져옴
- 하나의 topic에 여러 개의 consumer가 각각 다른 목적으로 존재
- topic에 입력된 데이터는 여러 consumer가 서로 다른 처리를 위해 여러 번 가져올 수 있음
message: kafka에서 다루는 데이터의 최소 단위. key-value를 가지며 메시지 전송시 파티셔닝에 이용됨topic: 메시지를 종류별로 관리하는 스토리지. broker에 배치되어 관리된다. 단일 카프카 클러스터에서 여러 종류의 메시지를 중계함
kafka 요청 처리 방식
- kafka가 요청을 처리할 때 두 개의 스레드 레이어를 사용
- 네트워크 스레드 : 클라이언트와의 이벤트 기반 비동기 I/O 처리를 수행
- 요청 핸들러 스레드 : 네트워크 스레드가 가져온 요청을 내용을 처리해서 필요한 응답 객체를 네트워크 스레드에 반환
디스크 영속화
- 카프카는 디스크 영속화를 하면서도 높은 처리량을 제공
- 데이터를 받아들이면서 장기 보존을 목적으로 영속화
- 메시지를 잃지 않는 전달 보증으로 ACK와 Offset Commit 개념이 도입됨
- ACK : 브로커가 메시지를 수신하였을 때 프로듀서에게 수신 완료했다는 응답
- Offset Commit : 컨슈머가 브로커로부터 메시지를 받을 때 컨슈머가 어디까지 받았는지 관리
- 카프카만 가지고는 데이터 유통만 가능.
- 각종 애플리케이션을 붙이기 위한 커넥터, proxy, 실시간 테이블 처리을 위한 ksqlDB 등을 지원하는 Confluent
- Confluent는 Apache Kafka에 대한 commit의 80% 이상을 담당
Confluent
- Confluent는 Kafka의 창시자가 설립
- 설치형 서비스 및 SaaS 서비스 제공
- 실시간 모니터링 툴 제공
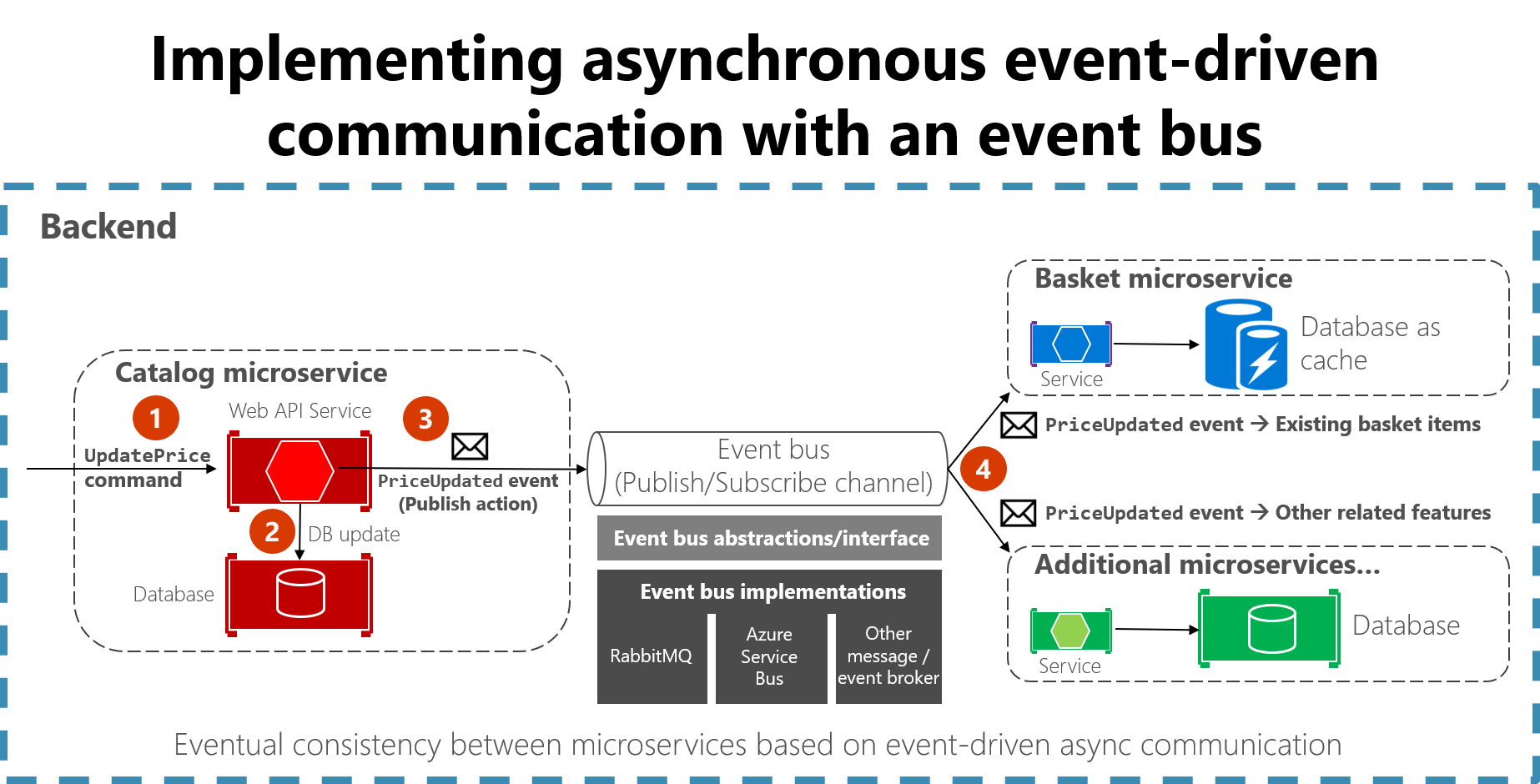
마이크로서비스
- 대표적인 것이 넷플릭스 아키텍처: 각 서비스간 연결이 중요하지만, 많아질수록 복잡해짐
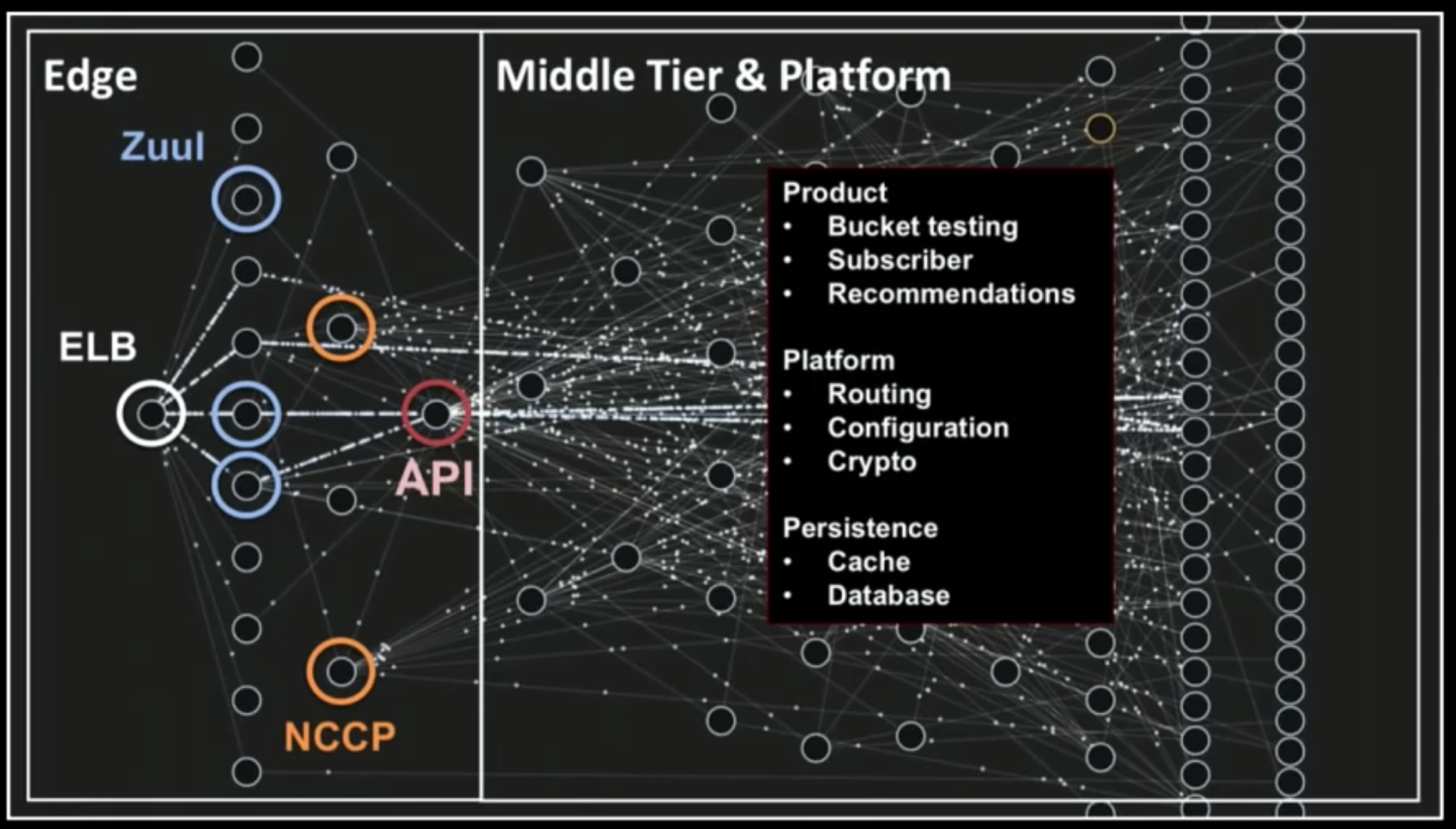
- 이벤트 기반 마이크로서비스에서 중요한 것이 event bus인데, confluent가 해당 역할을 함
Reference
'BigData' 카테고리의 다른 글
| 엘라스틱서치 (ElasticSearch) (0) | 2021.03.08 |
|---|