elasticsearch
엘라스틱서치
- 엘라스틱서치는 검색 엔진인 Apache Lucene으로 구현한 RESTful API 기반의 검색 엔진
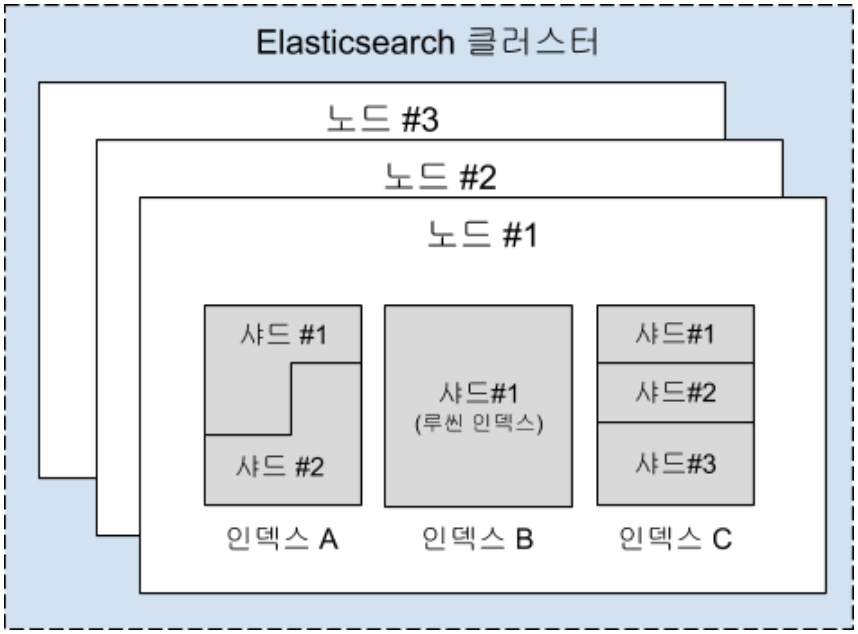
- 엘라스틱서치 내에 저장된 데이터를 Index라고 부르며, 각 인덱스는 한 개 이상의 샤드로 구성되어 있음
- 샤드는 Lucene 인덱스를 뜻하며, Lucene 인덱스는 엘라스틱서치 클러스터 내에서 인덱싱 및 데이터 조회를 위한 독립적인 검색엔진이다.
- 데이터를 샤드에 입력할 때, 엘라스틱서치는 주기적으로 디스크에 immuatable한 Lucene segment 형태로 저장하며, 이 작업 이후에 조회가 가능.
- 이 작업을 리프레쉬(Refresh)라고 부름
- 샤드는 한 개 이상의 segment로 구성
- segment 개수가 많아지면, 주기적으로 더 큰 segment로 병합된다. (Merge)
- 모든 segment는 immutable하기 때문에, 병합되는 segment가 삭제되기 이전에, 새로운 segment를 생성.
- 따라서 디스크 사용량에 변화가 생김. 병합 작업은 디스크 I/O 등 리소스에 민감하다.
단점
- 분산처리를 통해 실시간으로 처리하는 것으로 보이지만, 내부적으로 commit, flush 등의 작업을 거치므로 실시간은 아니다.
- 트랜잭션, Rollback을 지원하지 않음 (클러스터의 성능을 위해)
- 데이터의 업데이트를 지원하지 않음. 업데이트 명령이 오면 기존 문서를 삭제하고 새로운 문서 사용
- 대신에 Immutable하다는 장점이 있다.
- Segment가 Immutable한 이유는 캐싱 때문이다. Lucene은 읽기 속도를 높이기 위해 OS의 파일시스템 캐싱에 의존하고 있음. 빠른 액세스를 위해 hot segment를 메모리에 상주하게 유지시키는 식으로 작동한다. 참고
Reference